Rails 6.1, Ruby3.0.0(rc1)に上げるまでに踏んだ問題
趣味で動かしているRails6.0.x、Ruby 2.7.1のアプリ3つをRails 6.1、Ruby 3.0.0(rc1)にまで上げようと試みた。 そのときに遭遇した問題をまとめたもの。
ひとまずRails 6.1、Ruby 2.7.2まで上げることにした。 以下、その過程で踏んだ問題。
rails aborted! LoadError: cannot load such file -- listen
rails app:update を叩いたときに出てきた。
gem 'listen'
を追加。
Rails 6.1はActiveStorage周りのスキーマも変わっていて、 rails app:update を実行するとマイグレーションファイルが追加されるので実行をお忘れなく。
NoMethodError: undefined method `parent' for MyApplication::Application:Class
rails db:migrate を実行したときにrails-erdで出る。
Rails 6.1 support · Issue #363 · voormedia/rails-erd · GitHub の通り、issueは立っているが作者が1年ぐらい更新してないので更新されるか望み薄。
とりあえずフォーク版で修正してくれていたのでそれを使うようにした。
gem 'rails-erd', github: 'guapolo/rails-erd'
uninitialized constant NestedForm::BuilderMixin (NameError)
同じく rails db:migrate の時に発生。rails_admin の問題の様子。
config/initializers/rails_admin.rb に2行のrequireを追加した。
refs: uninitialized constant NestedForm::BuilderMixin · Issue #887 · sferik/rails_admin · GitHub
require "nested_form/engine" require "nested_form/builder_mixin"
NoMethodError: undefined method `assert_nothing_raised'
RSpecのSystemSpecで出るようになっていた。
rspec - Rails 6.1 upgrade: undefined method `assert_nothing_raised' - Stack Overflow
これと同じ問題だったのでspec/rails_helper.rb に以下を追加
config.include ActiveSupport::Testing::Assertions
SystemStackError - stack level too deep
developmentで試しに動作確認しようとしたら出た。
stacktrace的に meta_request というGemが怪しかったので試しにオフにしたら解決。
特に使っていなかったのでそのまま削除。
activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:174:in `block in as_json' activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:173:in `each' activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:173:in `as_json' activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:57:in `as_json' activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:174:in `block in as_json' activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:173:in `each' activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:173:in `as_json' activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:174:in `block in as_json' activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:173:in `each' activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:173:in `as_json' activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:57:in `as_json' activesupport (6.1.0) lib/active_support/json/encoding.rb:35:in `encode' activesupport (6.1.0) lib/active_support/json/encoding.rb:22:in `encode' activesupport (6.1.0) lib/active_support/core_ext/object/json.rb:42:in `to_json' meta_request (0.7.2) lib/meta_request/event.rb:46:in `block in json_encodable' meta_request (0.7.2) lib/meta_request/event.rb:66:in `block in transform_hash' meta_request (0.7.2) lib/meta_request/event.rb:60:in `each' meta_request (0.7.2) lib/meta_request/event.rb:60:in `inject' meta_request (0.7.2) lib/meta_request/event.rb:60:in `transform_hash' meta_request (0.7.2) lib/meta_request/event.rb:38:in `json_encodable' meta_request (0.7.2) lib/meta_request/event.rb:15:in `initialize' meta_request (0.7.2) lib/meta_request/app_notifications.rb:69:in `new' meta_request (0.7.2) lib/meta_request/app_notifications.rb:69:in `block in subscribe' meta_request (0.7.2) lib/meta_request/app_notifications.rb:81:in `block in subscribe'
NameError: uninitialized constant ActiveJob::Logging::LogSubscriber
ActiveJobの引数に巨大な値を指定するとログが一瞬で埋まるのでsnipするために挟んでいた。 6.0.xから6.1でこの辺が変わっていたみたい。
diff --git a/config/initializers/active_job_custom_logger.rb b/config/initializers/active_job_custom_logger.rb index 1b352a6..856338a 100644 --- a/config/initializers/active_job_custom_logger.rb +++ b/config/initializers/active_job_custom_logger.rb @@ -1,4 +1,4 @@ -require 'active_job/logging' +require 'active_job/log_subscriber' module ActiveJobCustomLogger def args_info(job) @@ -9,4 +9,4 @@ module ActiveJobCustomLogger end end -ActiveJob::Logging::LogSubscriber.prepend(ActiveJobCustomLogger) +ActiveJob::LogSubscriber.prepend(ActiveJobCustomLogger)
ArgumentError: You tried to define an enum named "bar_status" on the model "Hoge", but this will generate a instance method "_?", which is already defined by another enum.
enum値に日本語を使ってると(正確には英数字以外を使っていると)正規表現で消されてしまって重複メソッド扱いになりエラーとなる。 https://github.com/rails/rails/blob/v6.1.0/activerecord/lib/active_record/enum.rb#L205
一応issueにコメントだけしたけど、コーナーケースすぎるのでそもそもコメントしようか悩んだ…。 背景的にはローカライズが必要ない(する予定がない)のでそのまま日本語を入れていた。
https://github.com/rails/rails/issues/40804#issuecomment-751440989
2021/01/09追記
kamipoさんが6.1.1で直してくれた。感謝。
manifest unknown
Ruby, Railsと直接関係ないポカミス。 masterにマージしてimageを作る際に出た。
ruby:2.7.2-alpine3.10 なんてイメージはないので ruby:2.7.2-alpine3.12 に修正。
Step 1/22 : FROM ruby:2.7.2-alpine3.10 manifest for ruby:2.7.2-alpine3.10 not found: manifest unknown: manifest unknown
rails aborted! LoadError: Error loading shared library liblzma.so.5: No such file or directory (needed by /usr/local/bundle/gems/nokogiri-1.10.10/lib/nokogiri/nokogiri.so) - /usr/local/bundle/gems/nokogiri-1.10.10/lib/nokogiri/nokogiri.so
Rails 6.1、Ruby 2.7.2の段階で一回デプロイしておいた。 趣味なので多少エラーが出ても良いし、Ruby 3に関係ないところで問題があるなら切り分けて確認しておきたいため。
どこかで見たことがあるエラー、 prod環境の rails db:migrate 時に発生。
alpineだとありがちなイメージがあったのでこの機会にslim-busterに移行した。
イメージサイズが135MB->285MBになってしまった…。 とはいえ特に問題なく普通に動くのがコンテナのいいところ。
Ruby 3化
バージョン管理にasdfを使っているが、3.0.0が選べなかったので調べてたらここに行き着いた。
Increment ruby-build for Ruby 3.0.0 support by f440 · Pull Request #192 · asdf-vm/asdf-ruby · GitHub
ASDF_RUBY_BUILD_VERSION=v20201225 asdf install ruby 3.0.0 でインストール。
まず起動しようとするとcannot load such file -- webrick/httputils (LoadError) が出た。
全く心当たりが無いのでstacktraceを見ると、
/vendor/bundle/ruby/3.0.0/gems/mechanize-2.7.6/lib/mechanize.rb:12:in `<main>
太古に使ってたGemなので削除。
次に cannot load such file -- binding_of_caller.bundle (LoadError) が出た。
stacktraceを見ると、
/vendor/bundle/ruby/3.0.0/gems/binding_of_caller-0.8.0/lib/binding_of_caller.rb:9:in `<main>'
BetterErrorsを使うために入れていたけど、試しに消してみる。 Gemfile.lockを見ると、
pry-stack_explorer (0.5.1)
binding_of_caller (~> 0.7)
の依存でまだ残っていたのでpry-stack_explorerも消す。 これでようやくrails sで起動するようになった。
最近はirbも進化してるし、productionではpryを使ってないのでirbに移行しよう。 BetterErrorsも便利だったけどweb-consoleで十分かな。という断捨離の気持ちが得られた。 Rails触りはじめの頃に使ったアプリなので不要なgemがたくさん入ってしまっている…。
web-consoleはVimiumと干渉してまともにタイプできないことが一番きつい。 jsで入力キーを取得してpreタグの中で入れ込むような挙動になっているようなので、素直にinputタグにしてくれたら大丈夫そうだけど、色々フックされてるっぽいのでややこしそう…。 あるいは一時的にVimiumをオフにするショートカットキーなどがあればそれで対応する形になるか…。
Ruby公式もテスト用の circleci/ruby もRC版しかなかったので一旦RC1のイメージを使うようにした。
ruby:3.0.0-rc1-slim-busterにはgitが入っていなかったので、gitをapt-get installに追加。 この状態でデプロイして特に問題なく動作したので、あとは正式版のイメージが出たら切り替えようかな、というぐらい。 ちょくちょく動かないものがあって断捨離をしたけど、結果的に良かった気がする。
全体の所感としては依存が多くなるほどアップデートのときに大変で運用コストがかかるので極力依存を増やさずにものを作ろうという気持ちに改めてなった。
あと複数アプリで更新作業をしてると rails app:update の実行で config/environments の差分をちゃんと反映する作業が一番精神的に大変だった。
カスタム設定は末尾に記載してなるべく差分反映の影響を受けないところに置いておくのがいいのかもしれない。
2020年振り返り
2020年はほぼ在宅でずっと家から仕事をしていた。 家で仕事をするのはとても快適だったけど、仕事が趣味みたいなところがあるので無限に残業してしまうのが良くないという感想。 プライベートだとコードを書くにも種がなかったりするので、適度にコーディング以外のことをやるのだけれど、仕事があるとずーっとやってしまう。
という背景もあり、例年よりはプライベート活動が少なかった。 OSSに投げたPRは以下。
- googleapis/google-cloud-go
- SpannerのReadWriteTransaction中にpanicを起こすとセッションがリークする問題の修正
- aws/eks-charts
- googleforgames/agones
- helmのvalues.yamlでannotations/resourcesをつけるための修正
- Prometheus/Grafanaの更新
- Allocatorのログレベルを変更するための修正
- pingcap/tidb-operator
- helm chartが壊れていたので修正
- actions/toolkit
- GitHub Actionsのメタ情報の追加(job, runNumber, runId)
- matrix jobの場合にjobを一意に特定する情報がなかったのが辛かった
- GitHub Actionsのメタ情報の追加(job, runNumber, runId)
- GoogleCloudPlatform/k8s-node-termination-handler
- ノードを削除する際にslack通知する機能の追加
- ノード削除時に変なアラートが出ないか因果関係を確認する用に欲しかったので投げてみたら通った
- ノードを削除する際にslack通知する機能の追加
あんまりプライベートに時間を当ててなかった割には色々投げれたほうがかなぁと思っている。
自分のOSSプロダクトは地道にaction-slackの改善を行ってきた。 この前のリリースでちょうど今年20回目のリリースになり、v2.6.0からv3.8.1まで更新された。 来たPRで大変助かったものもあり、地道ながら成長させ続けられているので嬉しい。 GitHub Actionsはとにかくテストが書きにくいのでそのあたりが改善してほしいところ。
今年は家にいた比率がとても高かったけど、仕事以外で最も影響を与えたのは勉強会だったなと思う。 自分は勉強するときは一人で満足なタイプなので、主に地元の勉強会に参加するときは勉強会そのものというよりは人と話して新しい観点をもらう、というところがメインだった。 登壇内容が純粋に気になって参加するケースもあるけど、結局発表を見ると色々な疑問が出てくるのでその場で質問することのハードルが高くなったオンライン勉強会はあまり参加していなかった。 地元だとKyoto.rbに参加したときにみんなでトークテーマを考えてその話題について話すという体験をしたことがあり、その手の勉強会は自分が楽しく参加できるなぁと思った記憶がある。*1 とはいえなんだかんだオンライン勉強会の利点も受けていて本気で気になるけど地理的にちょっとなーと思うセッションも気軽に見れるようになったのでトータルのPros/Consはあんまり変わってないかもしれない。
在宅で働くという観点で言うと、トータル良かったけど在宅ならではだなと思う問題もあった。 やることが明確で後はやるだけ(コードを書くだけ)、みたいな状態では在宅のほうが圧倒的にパフォーマンスが良い。 あとはインフラ検証で無駄に時間が溶ける系も残業をしやすくなってるので相性が良かった(?)。 逆に言うと大枠は決まってるんだけど細かいコーナーケースが色々出てきて口頭とかで詳細な認識合わせをした後に進めるような仕事はやりにくい。 やりにくくなっている理由は口頭で気軽にちょっと話しかける、というハードルが上がっているからだと思う。 元々自分はそんなに口頭で話しかけるのが得意なタイプでもないので、わざわざテキストではなくボイスチャットが必要なので、と切り出すのに心理的ハードルがあった。 個人の感覚としてはみんな在宅で口頭で喋る機会が減ってるんだからあまり気にせず誘えばいいんじゃない、と思いつつも口頭で話すほどじゃないかな、みたいな心理と揺れている状態。 ある程度の在宅期間を経て気持ちの整理としては「必要があればあまり気にせず声をかける」になってきたけど、元々人の時間を使うのが苦手なので徐々に慣れていきたいところ。
あとは今回の件でITエンジニアは在宅になった人がかなり増えたと思うので、今後のITエンジニア業界は在宅があってかつ魅力的なところにどんどん人気が出るのかもしれない。 自分は会社で働くということに対しては大きくネガティブな要素はない*2けれど、出勤するためにかかる時間に対してはかなりネガティブに思っているので、今は在宅は魅力的だなと思う。*3 ただ最終的に家庭を持つと色々メリハリを付けることが難しくなると思うので、逆に出社したいと思うようになるかもしれない。
あと今年買った印象深いものたち。
- 昇降デスク(マーフィー2 120 DBR)
- この前に奥行きが浅い机を使っていて、手首が空中に浮いてる形で作業していたら異常に肩が凝ったので購入を決意
- 高さが変えれるのはおまけ程度だったけど後々響いてくる。いろんな状況に対応できるので良かった
- ワークチェア(ジオーネ BK)
- 在宅用に買ったと言うより在宅が始まる直前に椅子が壊れたので買った
- アーロンチェアとかも検討したけど、座った感じでそこまで響かなかったのでお手頃なやつを
- 強いて言うならレッグレストがあるやつを買えばよかった
- mac mini(Intel)
- mac miniスタンド
- 購入したmac miniのためにスタンドを買った
- 机が広くなるので良い
- Magic Mouse2
- iPhone 12 mini
- iPhone 11 Proを使っていたけど、やはりでかかった
- 12 miniを使って軽さや指が届くことに猛烈に感動した
- 夜景がきれいに取れる携帯であればサイズは小さいままで良かったんだ…
- スマホスタンド
- 机の上にあると通知が来た瞬間FaceIDでロック解除して通知内容が読めて便利
- タブレット アーム スタンド スマホ
- 寝室で寝転がりながら動画を見れるようになって快適になった
- 寝る前に夜ふかしをするようになってしまった原因の一つ
- Fitbit Sense
- ある日突然Verse2が再起動ループになってしまったので次の日にSenseを購入した
- その後サポートに問い合わせたら新しいVerse2を送ってもらえたが未だに開けていない*4
- Windowsデスクトップ
- ロジクール アドバンスド ワイヤレスマウス MX Master 3
- 良いマウスと聞いて買ったが、思ったよりは良くなかった
- 時間を置いて触るとしばらく反応しないのがネガティブ(PC側の青歯の問題?)
- BenQ 31インチモニター
- 元々24インチディスプレイだったWindowsマシンの入れ替え用
- Switchとかもこのディスプレイで遊んでいるが、大きくて良い
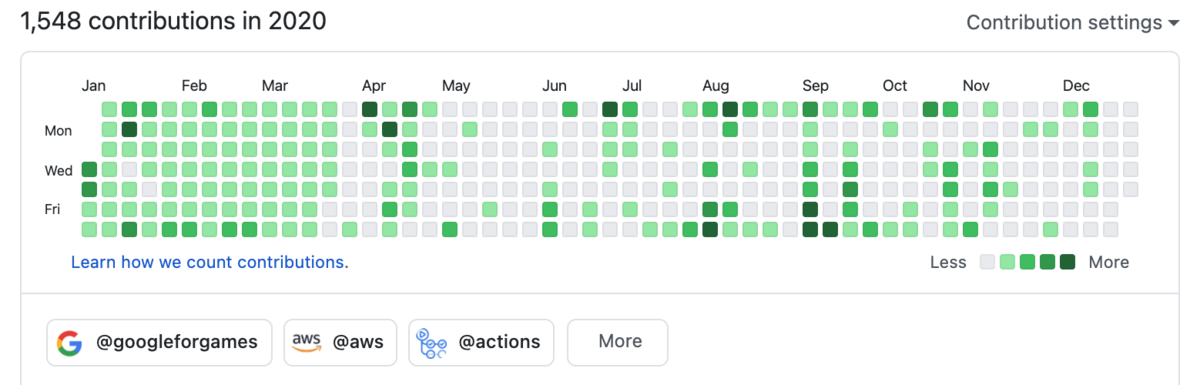
最後に草。 やはり大幅に減っている。(主に趣味プロダクトのコミット数が減っている)
GitHub Actionsライブラリのリリースを自動化する
action-slackというGitHub ActionsでSlack通知を行えるライブラリのリリースを自動化した。
package.jsonのバージョンを更新し、npm i を行ってmasterにpushすると変更されたバージョンでリリース作成まで行う。
流れとしては以下のような形。
- 各ブランチにpushした際に単体テストJobが走る
- 1のブランチがmasterかつ単体テストが通っていたらリリース準備Jobが走る
- package.jsonおよびpackage-lock.jsonを見てバージョンが変わっていた場合はリリース準備を行う
- 3でリリース準備を行った場合はリリースを作成(actions/create-release)する
手っ取り早くコードを見たい人は以下のリンクからどうぞ。
最初に悩んだのはGitHub Actionsのワークフロー内でコードをpushしたりタグをつけた場合は他のワークフローが発火しないということ。
例えばタグをpushするとactions/create-releaseがリリースを作成するワークフロー(WF A)があったときに、別のワークフローでタグをつけてpushしてもWF Aは発火しない。
これを回避するためにはPersonal Access Tokenを使うと回避できると記載されている。
refs: Events that trigger workflows - GitHub Docs
prepare-release Jobでは以下の処理を行っている。
- 「ifでmasterブランチを限定」し、needsで「test Jobが成功したこと」を保証する
GITHUB_TOKENにPersonal Access Tokenを指定して、actions/create-releaseが記載されているワークフローが発火させる
prepare-release: if: contains(github.ref, 'master') needs: [test] runs-on: ubuntu-latest steps: ... - run: npm run prepare-release env: GITHUB_TOKEN: ${{ secrets.GH_TOKEN }}
自分の場合は npm run prepare-release を実行するとbashスクリプトを実行し、その中で色々リリースに必要な操作を行っている。
prepare-release.sh
上記のスクリプトではpackage.jsonからバージョン情報を抽出し、メジャーバージョンを見て v3 ブランチなどにpushしつつ*1タグを付与する操作を行っている。
*1:1文字しか見てないので現状v9までしか正常に動作しない